NIM : 2301863521 Kelas : CB01 - CL Lecturer: Rulyna ( D4689 ) dan Henry Chong ( D4460 )
Linked List
Apa itu Linked List?
Linked List adalah bagian dari Struktur Data. Linked list atau dikenal juga dengan sebutan senarai berantai adalah struktur data yang terdiri dari urutan record data dimana setiap record memliki field yang menyimoan alamat/ referensi dari record selanjutnya (dalam urutan) elemen data yang dihubungkan dengan link pada linked list disebut Node. Biasanya didalam suatu lnked list, terdapat istilah head and tail.
• Head adalah elemen yang berada pada posisi pertama dalam suatu linked list
• Tail adalah element yang berada pada posisis terakhir dalam suatu linked list
Ada Beberapa macam Linked List, yaitu:
1.Single Linked List
Single Linked List merupakan suatu linked list yang hanya memiliki satu variabel pointer saja. Dimana pointer tersebut menunjuk ke node selanjutnya.Tempat yang disediakan pada satu area memori tertentu untuk menyimpan data dikenal dengan sebutan node atau simpul. Setiap node memiliki pointer yang menunjuk ke simpul berikutnya sehingga terbentuk satu untaian, dengan demikian hanya diperlukan sebuah variabel pointer. Susunan berupa untaian semacam ini disebut Single Linked List (NULL memilik nilai khusus yang artinya tidak menunjuk ke mana-mana. Biasanya Linked List pada titik akhirnya akan menunjuk ke NULL).
Contoh:
2. Double Linked List
Double Linked List Merupakan suatau linked list yang memiliki dua variabel pointer yaitu pointer yang menunjuk ke node selanjutnya dan pointer yang menunuk ke node sebelumnya. Salah satu kelemahan single linked list adalah pointer (penunjuk) hanya dapat bergerak satu arah saja, maju/mundur, atau kanan/kiri sehingga pencarian data pada single linked list hanya dapat bergerak dalam satu arah saja. Untuk mengatasi kelemahan tersebut, dapat menggunakan metode double linked list. Linked list ini dikenal dengan nama Linked list berpointer Ganda atau Double Linked List. Setiap head dan tailnya juga menunjuk ke NULL.
Contoh:
3. Circular Linked List
Circular Linked List merupakan suatu linked list dimana tail (node terakhir) menunjuk ke head(node pertama).Jadi tidak ada pointer yang menunjuk NULL ada 2 jenis Circular Linked List Yaitu:
• Circular Single Linked List
Single Linked List Circular adalah Single Linked List yang pointer nextnya menunjuk pada dirinya sendiri. Jika Single Linked List tersebut terdiri dari beberapa node,
maka pointer next pada node terakhir akan menunjuk ke node terdepannya.
Pengertian:
Single : artinya field pointer-nya hanya satu buah saja dan satu arah.
Circular : artinya pointer next-nya akan menunjuk pada dirinya sendiri sehingga berputar
Contoh:
• Circular Double Linked List
Merupakan double linked list yang simpul terakhirnya menunjuk ke simpul terakhirnya menunjuk ke simpul awalnya menunjuk ke simpul akhir sehingga membentuk suatu lingkaran.
Contoh:
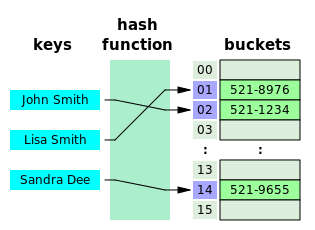
Hashing Table
Hash table (hash map) is a data structure that implements an associative array abstract data type, a structure that can map keys to values. A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found.
Ideally, the hash function will assign each key to a unique bucket, but most hash table designs employ an imperfect hash function, which might cause hash collisions where the hash function generates the same index for more than one key. Such collisions are always accommodated in some way.
Hash table (also, hash map) is a data structure that basically maps keys to values. A hash table uses a hash function to compute an index into an array of buckets or slots, from which the corresponding value can be found.
We will go through a basic Hash Map implementation in C++ that is supportinggenerictype key-value pairs with the help oftemplates. It is genuinely not a production-ready implementation of HashMap class, however it simply shows how this data structure can be implemented in C++.
Binary TreeUnlike Arrays, Linked Lists, Stack and queues, which are linear data structures, trees are hierarchical data structures. A binary tree is a tree data structure in which each node has at most two children, which are referred to as the left child and the right child. It is implemented mainly using Links.
Binary Tree Representation: A tree is represented by a pointer to the topmost node in tree. If the tree is empty, then value of root is NULL. A Binary Tree node contains following parts. 1. Data 2. Pointer to left child 3. Pointer to right child
A Binary Tree can be traversed in two ways: Depth First Traversal: Inorder (Left-Root-Right), Preorder (Root-Left-Right) and Postorder (Left-Right-Root) Breadth First Traversal: Level Order Traversal
Binary Search Tree In Binary Search Tree is a Binary Tree with following additional properties: 1. The left subtree of a node contains only nodes with keys less than the node’s key. 2. The right subtree of a node contains only nodes with keys greater than the node’s key. 3. The left and right subtree each must also be a binary search tree.
Binary Heap A Binary Heap is a Binary Tree with following properties. 1) It’s a complete tree (All levels are completely filled except possibly the last level and the last level has all keys as left as possible). This property of Binary Heap makes them suitable to be stored in an array. 2) A Binary Heap is either Min Heap or Max Heap. In a Min Binary Heap, the key at root must be minimum among all keys present in Binary Heap. The same property must be recursively true for all nodes in Binary Tree. Max Binary Heap is similar to Min Heap. It is mainly implemented using array.
Binary Search Tree
A binary search tree (BST), also known as an ordered binary tree, is a node-based data structure in which each node has no more than two child nodes. Each child must either be a leaf node or the root of another binary search tree. The left sub-tree contains only nodes with keys less than the parent node; the right sub-tree contains only nodes with keys greater than the parent node.
The BST data structure is the basis for a number of highly efficient sorting and searching algorithms, and it can be used to construct more abstract data structures including sets, multisets, and associative arrays.
Binary search trees keep their keys in sorted order, so that lookup and other operations can use the principle of binary search: when looking for a key in a tree (or a place to insert a new key), they traverse the tree from root to leaf, making comparisons to keys stored in the nodes of the tree and deciding, on the basis of the comparison, to continue searching in the left or right subtrees. On average, this means that each comparison allows the operations to skip about half of the tree, so that each lookup, insertion or deletion takes time proportionalto the logarithm of the number of items stored in the tree. This is much better than the linear time required to find items by key in an (unsorted) array, but slower than the corresponding operations on hash tables.
Frequently, the information represented by each node is a record rather than a single data element. However, for sequencing purposes, nodes are compared according to their keys rather than any part of their associated records. The major advantage of binary search trees over other data structures is that the related sorting algorithms and search algorithms such as in-order traversal can be very efficient; they are also easy to code.
Binary search trees are a fundamental data structure used to construct more abstract data structures such as sets, multisets, and associative arrays.
When inserting or searching for an element in a binary search tree, the key of each visited node has to be compared with the key of the element to be inserted or found.
The shape of the binary search tree depends entirely on the order of insertions and deletions, and can become degenerate.
After a long intermixed sequence of random insertion and deletion, the expected height of the tree approaches square root of the number of keys, √n, which grows much faster than log n.
There has been a lot of research to prevent degeneration of the tree resulting in worst case time complexity of O(n) (for details see section Types).
Binary search tree is a data structure that quickly allows us to maintain a sorted list of numbers.
It is called a binary tree because each tree node has maximum of two children.
It is called a search tree because it can be used to search for the presence of a number in O(log(n)) time.
The properties that separates a binary search tree from a regular binary tree is
All nodes of left subtree are less than root node
All nodes of right subtree are more than root node
Both subtrees of each node are also BSTs i.e. they have the above two properties
The binary tree on the right isn't a binary search tree because the right subtree of the node "3" contains a value smaller that it.
HEAP
Pengertian Heap Adalah struktur data yang berbentuk pohon yang memenuhi sifat-sifat heap yaitu jika B adalah anak dari A, maka nilai yang tersimpan di simpul A lebih besar atau sama dengan nilai yang tersimpan di simpul B.
Heap adalah complete binary tree (bukan binary search tree) yang mempunyai properties sebagai berikut:
Min Heap
Setiap node lebih kecil dari masing-masing childnya
Root merupakan node paling kecil, sedangkan node terbesar terletak pada leaf node
Max Heap
Setiap node lebih besar dari masing-masing childnya
Root merupakan node paling besar, sedangkan node terkecil terletak pada leaf node
Min-Max Heap
Heap dengan Min heap pada level ganjil dan Max heap pada level genap
Jenis-jenis Heap
1. Binary heap
adalah heap yang dibuat dengan menggunakan pohon biner.
2. Binomial heap
adalah heap yang dibuat dengan menggunakan pohon binomial.
Pohon binomial bila didefinisikan secara rekursif adalah:
• Sebuah pohon binomial dengan tinggi 0 adalah simpul tunggal
• Sebuah pohon binomial dengan tinggi k mempunyai sebuah simpul akar yang anak-anaknya adalah akar-akar pohon pohon binomial.
3. Fibonacci Heap
Fibonacci heap adalah kumpulan pohon yang membentuk minimum heap.
Pohon dalam struktur data ini tidak memiliki bentuk yang tertentu dan pada kasus yang ekstrim heap ini memiliki semua elemen dalam pohon yang berbeda atau sebuah pohon tunggal dengan tinggi Keunggulan dari Fibonacci heap adalah ketika menggabungkan heap cukup dengan menggabungkan dua list pohon.
TRIES
Tries atau prefix tree adalah suatu pohon struktur data yang terurut yang menyimpan data array, biasanya string. Kata tries diambil dari kata RETRIEVAL, karena tries dapat menemukan kata tunggal dalam kamus dengan hanya awalan katanya saja.
Tries sudah diterapkan ke banyak hal dalam kehidupan sehari-hari, contohnya pada web browser. suatu web browser dapat mengira atau mensugestikan kata-kata yang mungkin kita maksud saat kita mengetik huruf pertamanya saja. (autocomplete)
Contoh tries :
Pada gambar diatas menunjukan kata : ALGO, API, BOM, BOSAN, BOR.
Stack & Queue
STACK
DEFINISI STACK
Stack (Tumpukan) adalah kumpulan elemen-elemen data yang disimpan dalam satu lajur linear. Kumpulan elemen-elemen data hanya boleh diakses pada satu lokasi saja yaitu posisi ATAS (TOP) tumpukan. Tumpukan digunakan dalam algoritma pengimbas (parsing), algoritma penilaian (evaluation) dan algoritma penjajahan balik (backtrack). Elemen-elemen di dalam tumpukan dapat bertipe integer, real, record dalam bentuk sederhana atau terstruktur. Stack (tumpukan) sebenarnya secara mudah dapat diartikan sebagailist (urutan) dimana penambahan dan pengambilan elemen hanya dilakukan pada satu sisi yang disebut top (puncak) dari stack.
Operasi – operasi pada Stack
1. Push : digunakan untuk menembah item pada Stack pada Tumpukan paling atas. 2. Pop : digunakan untuk mengambil item pada Stack pada Tumpukan paling atas. 3. Clear : digunakan untuk mengosongkan Stack. 4. Create Stack : membuat Tumpukan baru S, dengan jumlah elemen kosong. 5. MakeNull : mengosongkan Tumpukan S, jika ada elemen maka semua elemen dihapus. 6. IsEmpty : fungsi yang digunakan untuk mengecek apakah Stack sudah kosong. 7. Isfull : fungsi yang digunakan untuk mengecek apakah Stack sudah penuh.
Kondisi nya yaitu : 1.TOP = NULL, arti nya menunjukan bahwa isi dari nilai TOP masih kosong atau belum ada data, jika di linked list kita menggunakan head tail yang menunjukan awal dan akhir dari data, maka disini kita hanya menggunakan top untuk menandakan nilai teratas dari suatu stack. 2.TOP = MAX-1, arti nya menunjukan bahwa stack sudah full. Kenapa harus -1 (minus 1), karena stack itu sama seperti array yaitu di mulai dari indeks ke 0, jadi kalau kita memesan 9 tempat, maka kita dapat menggunakan data sebanyak 8 (9-1) dimana di mulai dari 0 sampai 8. Operasi nya hampir sama dengan linked list, yaitu push dan pop, tetapi yang membedakan adalah top/peek, dimana top ini digunakan untuk kembali ke nilai paling atas dari suatu stack.
Stack mempunyai 2 variable yaitu TOP dan MAX, dimana nilai TOP menunjukan nilai paling atas dari suatu tumpukan sedangkan nilai MAX adalah jumlah maksimum elemen yang dapat ditampung oleh stack tersebut.
QUEUE
DEFINISI QUEUE
Queue merupakan suatu struktur data linear. Konsepnya hampir sama dengan Stack, perbedaannya adalah operasi penambahan dan penghapusan pada ujung yang bebeda. Penghapusan dilakukan pada bagian depan (front) dan penambahan berlaku pada bagian belakang (Rear). Elemen-elemen di dalam antrian dapat bertipe integer, real, record dalam bentuk sederhana atau terstruktur.
Tumpukan disebut juga “Waiting Line” yaitu penambahan elemen baru dilakukan pada bagian belakang dan penghapusan elemen dilakukan pada bagian depan. Sistem pada pengaksesan pada Queue menggunakan sistem FIFO (First In First Out), artinya elemen yang pertama masuk itu yang akan pertama dikeluarkan dari Queue. Queue jika diartikan secara harfiah, queue berarti antrian. Queue merupakan salah satu contoh aplikasi dari pembuatan double linked list yang cukup sering kita temui dalam kehidupan sehari-hari, misalnya saat anda mengantri diloket untuk membeli tiket.
Queue mempunyai 2 variable yaitu front dan rear, front menunjuk terhadap nilai paling depan dari suatu antrian, sedangkan rear menunjuk ke nilai paling belakang dari suatu antrian.
Kondisi nya yaitu :
1.Awal data selalu di mulai dengan front, dan setiap kali penambahan data, maka dia akan menjadi rear yang baru. 2.kalau front = rear = null maka dalam queue tersebut belum ada data.
Operasi nya sama dengan stack, tetapi maksud peek / front di queue adalah kembali ke data yang paling awal dari suatu queue.
Operasi-operasi pada Queue
1. Create Queue (Q) : membuat antrian baru Q, dengan jumlah elemen kosong. 2. Make NullQ (Q) : mengosongkan antrian Q, jika ada elemen maka semua elemen dihapus. 3. EnQueue : berfungsi memasukkan data kedalam antrian. 4. DeqQueue : berfungsi mengeluarkan data terdepan dari antrian. 5. Clear : Menghapus seluruh Antrian 6. IsEmpty : memeriksa apakah antrian kosong 7. IsFull : memeriksa apakah antrian penuh. Setelah mengetahui dasar dari queue, maka kita langsung saja ke coding nya :
struct data{ int angka; data *next; }*front=NULL,*rear=NULL,*curr;
Ini adalah data yang akan saya gunakan, yaitu angka sebagai nilai yang akan di push, lalu next sebagai pointer untuk menunjuk ke data selanjutnya yang berada di depan rear(data paling belakang), front untuk menunjukan nilai yang paling pertama dari suatu queue, rear untuk menunjukan nilai paling belakang dari suatu queue.
Kenapa front dan rear diberi nilai NULL? Agar memberi tahu kepada compiler bahwa nilai front dan rear dimulai dengan NULL, sehingga perintah dapat dengan jelas di laksanakan.
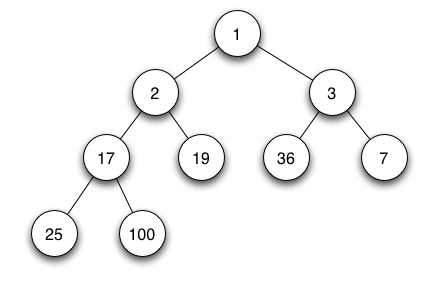
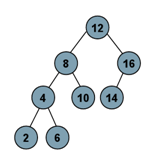
AVL Tree adalah Binary Search Tree yang memiliki perbedaan tinggi/ level maksimal 1antara subtree kiri dan subtree kanan. AVL Tree muncul untuk menyeimbangkanBinary Search Tree. Dengan AVL Tree, waktu pencarian dan bentuk tree dapat dipersingkat dan disederhanakan.
Contoh AVL Tree
Tree diatas merupakan AVL Tree karena perbedaan tinggi antara subtree kiri dan subtree kanan kurang dari atau sama dengan 1.
Contoh yang bukan AVL Tree
Tree diatas bukan termasuk AVL Tree karena perbedaan tinggi antara subtree kiri dan sybtree kanan untuk 8 dan 18 lebih besar dari 1.
Penambahan node di AVL Tree
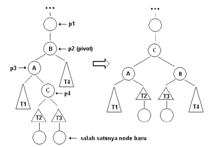
Untuk menjaga tree tetap imbang, setelah penyisipan sebuah node, dilakukan pemeriksaan dari node baru → root. Node pertama yang memiliki |balance factor| > 1 diseimbangkan.Proses penyeimbangan dilakukan dengan:Single rotation dan Double rotation.
Single Rotation
Single rotation dilakukan bila kondisi AVL tree waktu akan ditambahkan node baru dan posisi node baru seperti pada gambar 2. T1, T2, dan T3 adalah subtree yang urutannya harus seperti demikian serta height- nya harus sama (≥ 0). Hal ini juga berlaku untuk AVL tree yang merupakan citra cermin (mirror image) gambar 2.
Double Rotation
Double rotation dilakukan bila kondisi AVL tree waktu akan ditambahkan node baru dan posisi node baru seperti pada gambar 3. T1, T2, T3, dan T4 adalah subtree yang urutannya harus seperti demikian. Tinggi subtree T1 harus sama dengan T4 (≥ 0), tinggi subtree T2 harus sama dengan T3 (≥ 0). Node yang ditambahkan akan menjadi child dari subtree T2 atau T3. Hal ini juga berlaku untuk AVL tree yang merupakan citra cermin (mirror image) gambar 3.
Menghapus node di AVL Tree
Proses menghapus sebuah node di AVL tree hampir sama dengan BST. Penghapusan sebuah node dapat menyebabkan tree tidak imbang Setelah menghapus sebuah node, lakukan pengecekan dari node yang dihapus → root. Gunakan single atau double rotation untuk menyeimbangkan node yang tidak imbang. Pencarian node yang imbalance diteruskan sampai root.




 The BST data structure is the basis for a number of highly efficient sorting and searching algorithms, and it can be used to construct more abstract data structures including sets, multisets, and associative arrays.
Binary search trees keep their keys in sorted order, so that lookup and other operations can use the principle of binary search: when looking for a key in a tree (or a place to insert a new key), they traverse the tree from root to leaf, making comparisons to keys stored in the nodes of the tree and deciding, on the basis of the comparison, to continue searching in the left or right subtrees. On average, this means that each comparison allows the operations to skip about half of the tree, so that each lookup, insertion or deletion takes time proportional to the logarithm of the number of items stored in the tree. This is much better than the linear time required to find items by key in an (unsorted) array, but slower than the corresponding operations on hash tables.
Frequently, the information represented by each node is a record rather than a single data element. However, for sequencing purposes, nodes are compared according to their keys rather than any part of their associated records. The major advantage of binary search trees over other data structures is that the related sorting algorithms and search algorithms such as in-order traversal can be very efficient; they are also easy to code.
Binary search trees are a fundamental data structure used to construct more abstract data structures such as sets, multisets, and associative arrays.
The BST data structure is the basis for a number of highly efficient sorting and searching algorithms, and it can be used to construct more abstract data structures including sets, multisets, and associative arrays.
Binary search trees keep their keys in sorted order, so that lookup and other operations can use the principle of binary search: when looking for a key in a tree (or a place to insert a new key), they traverse the tree from root to leaf, making comparisons to keys stored in the nodes of the tree and deciding, on the basis of the comparison, to continue searching in the left or right subtrees. On average, this means that each comparison allows the operations to skip about half of the tree, so that each lookup, insertion or deletion takes time proportional to the logarithm of the number of items stored in the tree. This is much better than the linear time required to find items by key in an (unsorted) array, but slower than the corresponding operations on hash tables.
Frequently, the information represented by each node is a record rather than a single data element. However, for sequencing purposes, nodes are compared according to their keys rather than any part of their associated records. The major advantage of binary search trees over other data structures is that the related sorting algorithms and search algorithms such as in-order traversal can be very efficient; they are also easy to code.
Binary search trees are a fundamental data structure used to construct more abstract data structures such as sets, multisets, and associative arrays.
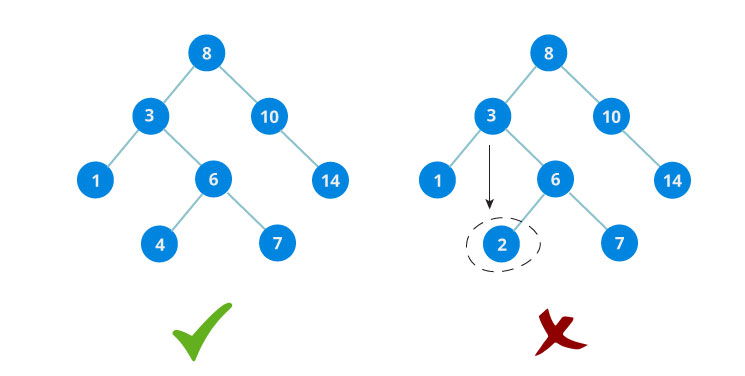





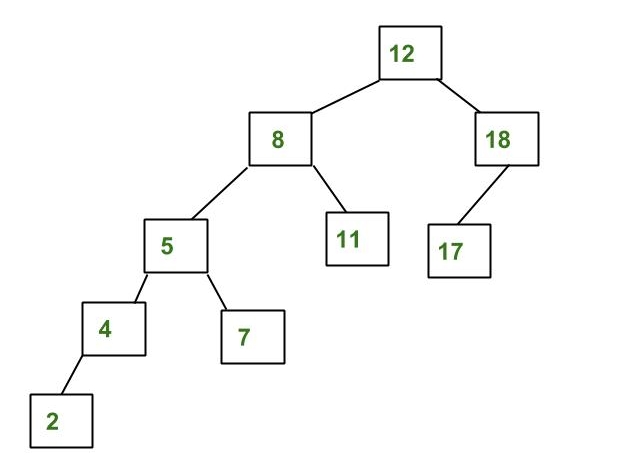 Tree diatas bukan termasuk AVL Tree karena perbedaan tinggi antara subtree kiri dan sybtree kanan untuk 8 dan 18 lebih besar dari 1.
Tree diatas bukan termasuk AVL Tree karena perbedaan tinggi antara subtree kiri dan sybtree kanan untuk 8 dan 18 lebih besar dari 1.

No comments:
Post a Comment